
The only real problem the professional software developers are facing these days is complexity. There are only two meaningful choices here: to reduce complexity or to fight it. We know many patterns, algorithms, languages, and tools that help you to make the task less complicated. However, there are only two approaches we can embrace it instead.
The first one, called Object-Oriented Programming (OOP). It provides developers with a way to design extremely complex solutions while focusing on developing only a small portion of it at the time. The OOP enables the developer to implement the program logic as a set of relationships between several objects that interact with each other using public interfaces. Objects have the following features:
The Railway-Oriented Programming allows the developer to design the program logic as one or several processes. Each process is a sequence of tasks sharing a common context.
Scott Wlaschin introduced the concept of Railway-Oriented Programming in his presentation on the “F# for fun and profit” website. He promotes it as the advantage of a functional programming language. I have discovered that we can use this approach in almost any programming language. Developers shall apply this pattern at the design stage, not the coding. In that case, one can avoid the obvious risk to make the code more complex instead of simplifying it.
The advantages of using the Rails pattern are the following:
When deciding to use this pattern, developers need to consider the following shortcomings:
The idea of the Rails pattern is straightforward. The following diagram shows the process that consists of three tasks (A, B, and C). Each task in the process must wait for the data produced by the previous operation.
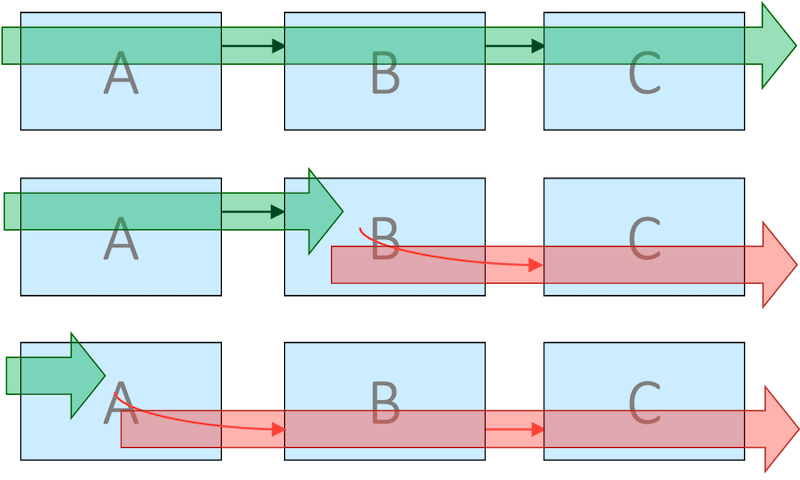
There are many possible scenarios for executing this process. This diagram illustrates only three of them:
The Rails pattern makes sure that both success and failure are treated universally across all tasks in the process. To accomplish that, every step in the sequence is responsible for validating data and handling exceptions. In case of an error, the task poisons the context by adding an error message. All steps will be executed in the same sequence, no matter which one has failed. The poisoned context shall fall through the rest of the route.
Let me illustrate using the Rails pattern using JavaScript and NodeJS. Let’s assume you have the following data encoded in JSON format and stored in a file:
{
"name": "John Doe",
"age": 35
}Our goal is to read this file and output the name to the screen. We design a simple process that consists of five steps:
’name’Some developers like a purely functional style of coding. They may compress all five steps to a single Excel-like function. In that case, the application code may look like this:
var fs = require('fs');
console.log("User name is ",
JSON.parse(fs.readFileSync(String(process.argv.slice(2), 'utf8')).name));To test the app, enter the following command:
$ node test.js example.json
User name is Jon DoeEven though the application is working, it is not very reliable. If anything goes wrong, it will just throw an exception. More, the code written in this style is unreadable, difficult to test, and dangerous to modify.
We can rewrite this code using the classic procedural programming style:
var fs = require('fs');
var fname = process.argv.slice(2);
fname = String(fname);
var data = fs.readFileSync(fname, 'utf8');
var obj = JSON.parse(data);
console.log("User name is ", obj.name);The code is more readable. Splitting the program to independent tasks makes it much easier to read and test.
The code is still short. However, as soon as you begin to add data validation and error handling to this code, it will start to grow. Moreover, the error handling will break the original workflow, make the code unreadable, difficult to test, and dangerous to modify.
Let’s write the code exactly as we designed the process. It consists of five steps:
// **** Main code *************************
var context = initContenxt();
context = validateParams(context);
context = readFromFile(context);
context = validateData(context);
displayResult(context);The approach requires implementing every task as an independent function with a unified interface. This way, we have better control over the application flow. The code is much larger, but it is also much cleaner.
We can use business domain terminology to describe the flow. We can add error handling without losing readability. The code is already optimized for unit testing. You may change the order in which the tasks are executed. It is much easier to design, develop, and debug. Let’s review every step individually.
First, we need to create the process context. It is an object that collects the data and reflects the current state of the workflow shared by all tasks. Implementation of the context object may vary depending on the language. In our example, our context looks like this:
//----------------------------------------------------
function initContext() {
var context = {
status: "OK",
fname: null,
error: null,
data: null,
hasError: function () {
return this.status != "OK";
},
setError: function (msg) {
this.status = "ERROR";
this.error = msg;
return this;
},
setException: function (ex) {
this.status = "EXCEPTION";
this.error = ex.message;
return this;
}
}
return context;
}A context is an object that can be in one of two states: Success or Failure. When an error happens, the task switches the state of the context object from Success to Failure. All process functions can use the context to store and pass data.
In the Railway pattern, every task is responsible for validating data context and input parameters. Even the initial state of the process may contain errors, so the first statement of every function is to checks the state of the context. If the context has failed already, the operation shall not proceed (fall through).
The task can interrupt the execution at any time, but it must return the process context in any case:
//----------------------------------------------------
function validateParams(context) {
if (context.hasError()) return context;
if (process.argv.length < 3) return context.setError("Provide file name");
context.fname = String(process.argv.slice(2));
if (fs.existsSync(context.fname)) {
return context;
} else {
return context.setError("File '" + context.fname + "' was not found");
}
}As you can see, the code is readable and easy to test.
The Railway pattern provides a “smooth ride” experience. It means that task functions shall never throw exceptions. The only way to return an error is by “poisoning” the context. That means that any exceptions that happened inside the function shall be converted to a failed state of the process context.
//----------------------------------------------------
function readFromFile(context) {
if (context.hasError()) return context;
try {
var obj = JSON.parse(fs.readFileSync(context.fname, 'utf8'));
context.data = obj;
}
catch (e) {
return context.setException(e);
}
return context;
}In case of successful execution, the task function performs the IO operations and returns the data by adding them to the context.
In this example, we combine all data validation into a single function. In a real scenario, you may want to implement every validation task separately so that you can reuse it.
//----------------------------------------------------
function validateData(context) {
if (context.hasError()) return context;
try {
var name = context.data.name;
if (!name || 0 === name.length) return context.setError("Invalid name");
if (context.data.age == null) return context.setError("Age is missing");
var age = context.data.age;
if (age != parseInt(age, 10)) return context.setError("Invalid age");
}
catch (e) {
return context.setException(e);
}
return context;
}Note that you can add many more validations to the code without losing readability. Here are some suggestions on how to use validation tasks:
The final task does not have to return the context:
//----------------------------------------------------
function displayResult(context) {
if (context.hasError()) {
console.error(context.status, ":", context.error);
} else {
console.log("User name is ",context.data.name);
}
}As you can see, you may postpone the error-based decision making until the end of the process. Use this opportunity to log the results of the process execution and communicate it to users. You may even store the entire context in the log for debugging purposes.
The Railway pattern is not a universal solution, but it has distinct advantages:
Watch the original lecture of Scott Wlaschin. Railway Oriented Programming — error handling in functional languages:
Sergey Kucherov