
This year marks 30 years since Berners-Lee began developing the Hypertext Markup Language (HTML). Simply put, we have come a long way since then. Starting from the excitement of new technology and all the way to the web addiction and censorship, we have seen cracked passwords, identity theft, computer viruses, worms, and now even ransomware. Did you ever wonder why the Internet remains so unstable and vulnerable? Where did we go wrong? Let’s find it out.
HTML 1.0, published in 1993, included only 13 elements (counting only those that have survived until today):
a, address, base, dd, dir, dl, dt, h1..h6, li, p, plaintext, title, ulThe most significant of these, of course, is the “anchor” (a). It provides the functionality that defines the first two letters in the title of the standard—hypertext. Without anchors (or links), HTML would be just another text markup language. It is the ability to refer the user to any document in the world using a universal resource locator (URL) that has created a fantastic phenomenon called the World Wide Web. Two years later, additional useful elements were added to HTML: html,head, body, as well as elements for creating forms, tables and images.
The last element arguably played the most significant role in the history of the Internet. By giving the browser the ability to display not only text, but also pictures, we made the new technology attractive not just for a small group of scientists and computer geeks, but also for millions of end users. We can safely say this innovation even prompted the industry to increase the speed of the Internet and make it available for mass users. However, there is another feature of this HTML element that has great historical significance. Look here:
<img src="http://ibm.com/ibm-logo.gif" />Since you could not embed (at that time) a binary image into a text file, the img element has an attribute that points to the place where the browser can find the required resource. This simple idea was the key to a great invention.
The key that we never turned.
HTML 2.0 was published in November 1995. Everyone was fascinated with the new features, and most likely the reason why no one had a wit to ask: why don’t we let all the other HTML elements also use this attribute? Imagine this:
<h1 src="/website/info/title"> </h1>This code means that the browser must load the content of the heading from the provided URL. Maybe it doesn’t make much sense for such a small element, but what about a div or an article?
<article src="/parts/article/blog1298" />Does it make sense now? I know that in 1993 the Internet speed was not as high as it is now. The new HTML features have already taken most of the existing bandwidth, and the HTTP protocol was not top notch. However, there was no reason not to allow such a feature in the first place.
You are probably wondering what impact this feature could have on the future of the WWW. By itself, perhaps not so great. But if we add another trait, the result would make an enormous difference. When the browser displays the page, it translates the HTML code into the in-memory Document Object Model (DOM). This model remains static until the browser receives a request to replace it with another HTML document. That is not how the computer software worked even in 1993. At the time when Netscape Navigator replaced the Mosaic browser, the Lotus 123 was already ten years old, and VisiCalc was even older. The idea of calculating the state of a document as a function of changes made by the user was already well known and quite simple to implement. Unfortunately, no one decided to apply it to browsers. Imagine what it would be like if the HTML 2.0 introduced the following feature:
<div id="name">George</div>
<h1>Welcome, $name</h1>Just as in a spreadsheet, you can refer to the contents of other cells, an HTML document could allow the use of variables that point to the values of other elements. For example, the above code would be rendered as a heading Welcome, George. Variables will make even more sense when they appear in a URL:
<article src="http://server.com/blog/$name"></article>For the above code, a browser would download the content of the article from the URL http://server.com/blog/George. And if the value of the name element changes, the browser would update the contents of just this element. As usual, it is up to the server to determine the application logic to generate the output. There is no need for AJAX and JavaScipt. This new, never-introduced feature would make it easy to implement a search box with dynamic prompts:
<input list="find" type="text" id="term" />
<datalist id="find" src="http://server.com/search/$term" />It is much safer to evaluate expressions than to execute a script, which can lead to unpredictable consequences. To make it even more compatible with spreadsheets, HTML should allow the use of functions sach as this one:
@CONCATENATE(first,", ",last);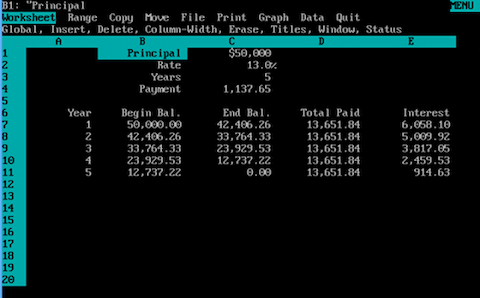
These features eliminate the need for JavaScript, shadow DOM, and other expensive and particulary insecure features. The browser would automatically calculate changes in the DOM based on user input. Today, this is typically referred to as Reactive Programming. It is unfortunate it took us 26 years to figure it out. Is it too late to implement it now?
You might think the latest versions of HTML5 + CSS3 + JS are enough for modern needs. I don’t believe so. We are still struggling with a simple user interface, even when we use complex JS frameworks such as Angular. What about web components? Will they make web programming faster, easier and safer? Maybe, maybe not. All I know is that it’s extremely easy to implement web components on top of the HTML standard that we never had. Say hello to the element define:
<head>
<define tag="login" src="http://server.com/components/login">
<define tag="footer" src="http://server.com/components/footer">
</head>
<body>
<login toremember="yes" />
...
<footer />
</body> That’s it. The page behind the URL specified in the src attribute is a regular HTML file. It may also contain variables, functions, as well as links to other components. The new style web components can be reused, not only on a same website, but also as a standard library across the Internet. The HTTP/2 protocol includes many useful features that will allow the new HTML to thrive. JavaScript can still be helpful, but in most cases, it will just be obsolete. When was the last time you had a need to use a macro in a spreadsheet?
Sergey Kucherov